La synthèse des protéines
1. L'acide désoxyribonucléique, le matériel héréditaire
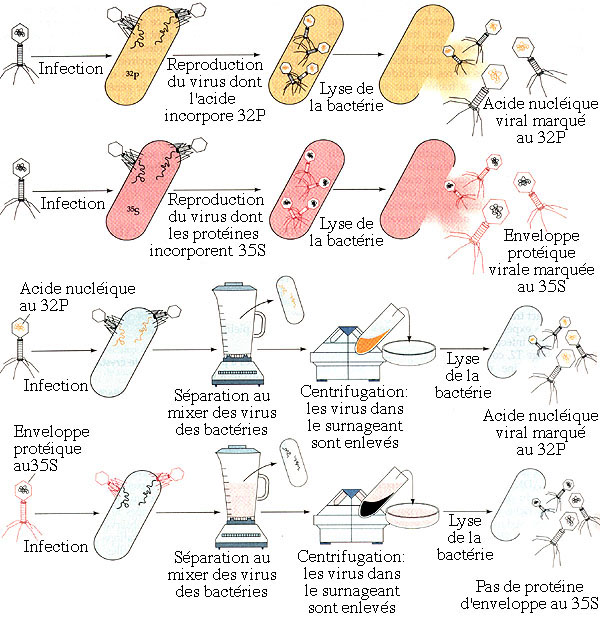
1.1 Expérience de Hershey et Chase
On savait, depuis les années 1950, que les chromosomes contiennent de l'acide nucléique et des protéines. L'expérience de Hershey et Chase, réalisée pour la première fois en 1952, permet de déterminer quel composant, parmi ces deux espèces moléculaires, porte les informations héréditaires.
Les virus sont des parasites obligatoires qui ne peuvent se reproduire que dans les cellules qu'ils infectent. Ce sont les plus petits organismes connus, de 5 à 200 nm, et ils sont constitués de deux parties: une enveloppe protéique contenant une molécule d'acide nucléique. Certains virus sont baptisés bactériophages (on dit souvent plus simplement "phages") car ils s'attaquent à des cellules bactériennes. Les phages du groupe T ("T" pour "Type") appartiennent aux virus complexes, car ils possèdent une tête et une queue; il en existe 7 types: T1 à T7.
L'expérience de HERSHEY et CHASE permet de savoir quel composant viral, acide nucléique ou protéine, pénètre la cellule pour servir de plan pour la reproduction virale. On cultive d'une part des virus bactériophages T2 sur des bactéries elles-mêmes élevées sur un milieu contenant du soufre sous sa forme isotopique 35S radioactive. Les protéines virales formées, qui contiennent du soufre, sont dès lors marquées radioactivement. En réalisant d'autre part une culture semblable sur un milieu où le phosphore est présent sous la forme de l'isotope radioactif 32P, on marque distinctement les acides nucléiques viraux. Le marquage est spécifique (protéines marquées au 35S et acides nucléiques marqués au 32P) puisque les acides nucléiques ne comportent pas d'atome de soufre et les protéines aucun atome de phosphore. Après avoir séparé, dans chacune des deux cultures, les virus, tous marqués, des bactéries qui les ont reproduits, on infeste simultanément deux nouvelles cultures bactériennes, chacune avec une souche différente des phages distinctement marqués. Les mélanges sont ensuite agités dans un mixer pour détacher les virus des bactéries, puis sont centrifugés pour concentrer les bactéries dans le culot et les virus dans le liquide surnageant, que l'on élimine. On constate, en analysant les culots bactériens grâce aux traceurs radioactifs, que seul l'acide nucléique viral, marqué au 32P, a pénétré les bactéries, l'enveloppe protéique virale, marquée au 35S, demeurant à la surface de la bactérie. Une fois l'infection initiée, on peut séparer les bactéries infectées des enveloppes virales vides sans que l'opération n'affecte la reproduction virale: un peu plus tard, les bactéries éclatent, libérant une nouvelle génération de phages.
Schémas illustrant l'espérience de Hershey et Chase (d'après Purves, Horians et Heller, modifié).
L'expérience démontre clairement que l'acide nucléique viral constitue le matériel héréditaire des virus, c'est-à-dire les "plans de construction" pour une nouvelle génération virale, l'"usine de fabrication" étant la cellule infectée.
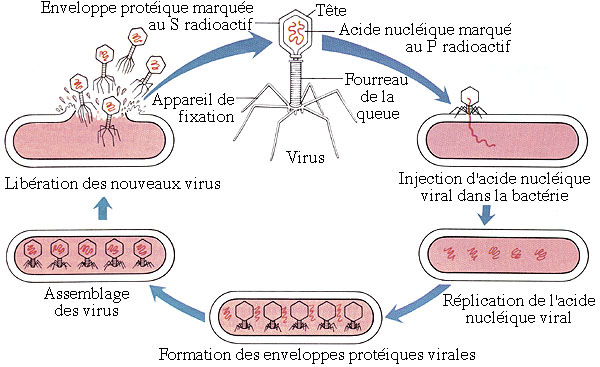
Schéma illustrant le cycle de vie d'un virus du groupe T (d'après Mader, modifié).
1.2 Structure de l'acide désoxyribonucléique
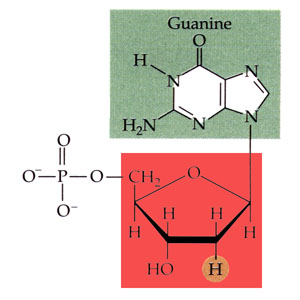
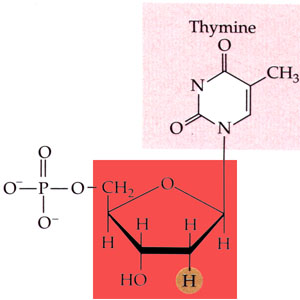
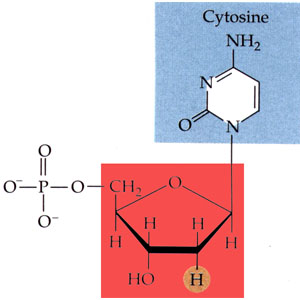
L'acide désoxyribonucléique ou ADN (DNA en anglais) est un très long polymère de nucléotides. Chaque nucléotide est constitué d'une molécule de désoxyribose (soit le glucide ribose ayant perdu un atome d'oxygène) lié d'un côté à une base purique (adénine ou guanine, molécules formées de deux cycles) ou à une base pyrimidique (thymine ou cytosine, molécules formées d'un cycle unique), et liée de l'autre côté à un ion phosphate, dont la présence confère le caractère acide à la molécule. Il existe donc quatre nucléotides différents. Les nucléosides correspondants sont réduits à l'association du désoxyribose et d'une base (ils correspondent aux nucléotides sans leur ion phosphate) et se nomment désoxyadénosine, désoxyguanosine, désoxythymidine et désoxycytidine.
|
|
|
|
Structure chimique de la désoxyadénosine phosphate, l'un des quatre nucléotides de l'acide désoxyribonucléique (la base purique est en jaune et le désoxyribose en rouge). |
Structure chimique de la désoxyguanosine phosphate, l'un des quatre nucléotides de l'acide désoxyribonucléique (la base purique est en vert et le désoxyribose en rouge). |
|
|
|
|
Structure chimique de la désoxythymidine phosphate, l'un des quatre nucléotides de l'acide désoxyribonucléique (la base pyrimidique est en rose et le désoxyribose en rouge). |
Structure chimique de la désoxycytidine phosphate, l'un des quatre nucléotides de l'acide désoxyribonucléique (la base pyrimidique est en bleu et le désoxyribose en rouge). |
Les bases azotées des nucléotides de l'ADN peuvent former entre elles des liaisons de faible énergie: les ponts hydrogène. En effet, si un atome est lié à un atome très électronégatif, il peut former une liaison faible avec un autre atome électronégatif porteur d'un doublet d'électrons non liant. Cette interaction, appelée "pont hydrogène", est plus faible que la plupart des liaisons chimiques (son énergie de dissociation vaut environ 30 kJ/mol ou 7 kcal/mol), mais néanmoins plus forte que les simples forces intermoléculaires de Van der Walls.
Etant donné que l'adénine forme deux ponts hydrogène avec la thymine, et que la guanine en forme trois avec la cytosine (c'est ce que l'on appelle l'appariement des bases complémentaires), la molécule d'ADN, polymère de nucléotides, est donc constituée de deux brins complémentaires reliés transversalement par des ponts hydrogènes. Ces deux brins sont parfaitement complémentaires, étant donné l'unicité des liaisons A-T et C-G.
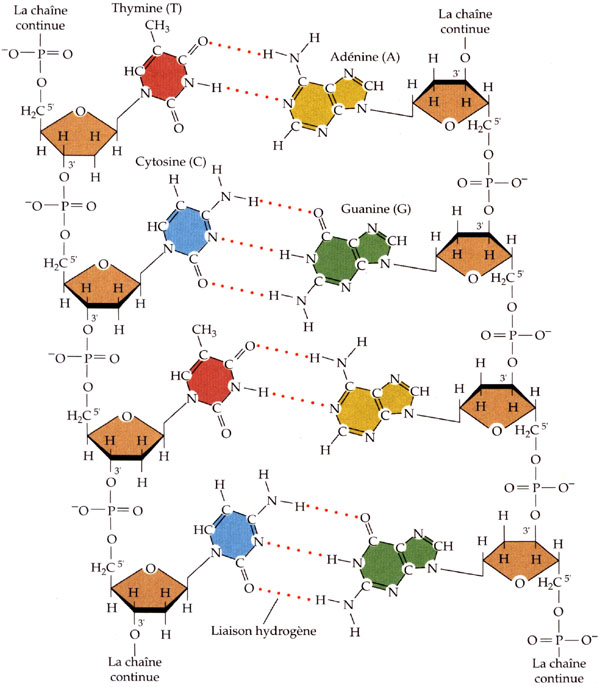
Structure fine de la molécule d'acide désoxyribonucléiques (d'après Purves, Horians et Heller).
Watson et Crick ont montré que la molécule d'ADN a la forme d'une double hélice dextrogyre d'environ 2 nm de large, à savoir qu'elle prend la forme d'un échelle torsadée qui tourne à droite dont les "montants" sont constitués par la succession alternée de désoxyriboses et de phosphates, et dont les barreaux de largeur constante sont faits chacun d'une base purique encombrante (à deux cycles) unie à une base pyrimidique moins encombrante (à un cycle).
Le fait que la double hélice d'ADN tourne à droite (et non à gauche comme cela aurait pu) chez tous les organismes chez qui cela a été étudié, constitue un point commun remarquable qui plaide en faveur d'une origine évolutive commune unique.
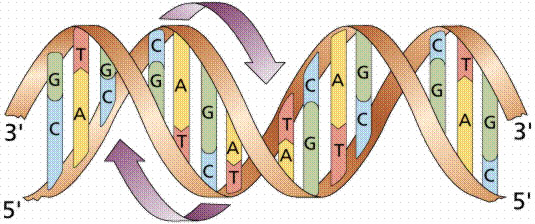
Structure hélicoïdale de la molécule d'acide désoxyribonucléiques (d'après Purves, Horians et Heller). La largeur de la double hélice est de 2 nm.
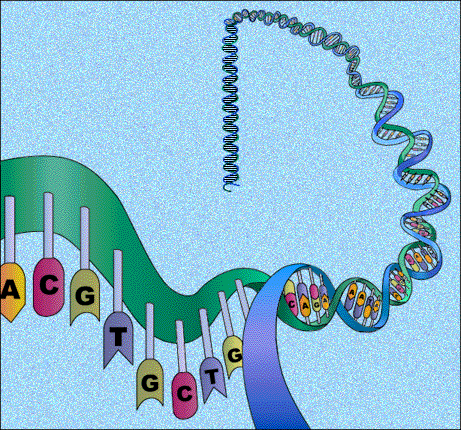
Structure hélicoïdale de la molécule d'acide désoxyribonucléiques (d'après http://www.ama-assn.org/ama/upload/images/36/dna.gif).

Modèle moléculaire de la molécule d'acide désoxyribonucléiques (d'après http://finkbeiner.com/Scientific/Images/DNA.jpg).
Le génome d'un organisme, c'est-à-dire l'ensemble des informations héréditaires nécessaires à la survie, au développement et à la reproduction de celui-ci, est fait d'ADN contenu, chez les eucaryotes, dans le noyau cellulaire, les mitochondries ainsi que dans les chloroplastes chez les végétaux. L'un des plus longs génomes connus, beaucoup plus long que le génome humain, lui-même de taille moyenne, est celui du muguet Convallaria majalis, et comprend 91.109 nucléotides!
|
Le tableau suivant donne quelques exemples de longueur de génomes d'organismes variés. Notons que le virus de la grippe présente un génome formé d'un simple brin d'ARN (acide ribonucléique), mais que tous les autres sont faits d'une double hélice d'ADN.

Souris des demeures Mus musculus, Muridae, Mammifère (Maison à Hamois, Condroz, Province de Namur, Belgique - 23/08/1988 - Diapositive originale réalisée par Eric Walravens). |
|
1.3 Réplication de l'acide désoxyribonucléique
En cours d'interphase, l'ADN doit se répliquer, pareil à lui-même, afin de fournir, pour la mitose suivante, deux exemplaires égaux, complets et parfaitement identiques du matériel héréditaire. Au cours de cette opération, chaque brin va servir de modèle pour la confection d'un nouveau brin complémentaire:
On parle de réplication semi-conservatrice car chaque nouvelle molécule comprend un brin ancien original associé à un nouveau.
Notons que la molécule d'ADN s'ouvre simultanément en de très nombreux endroits pour se répliquer, afin d'effectuer l'opération complète en un temps restreint.

Réplication de l'ADN, d'après www.contusalud.com/website/folder/ sepa_noticias_genoma.htm, repris et modifié de www.cyrion.org/about.html
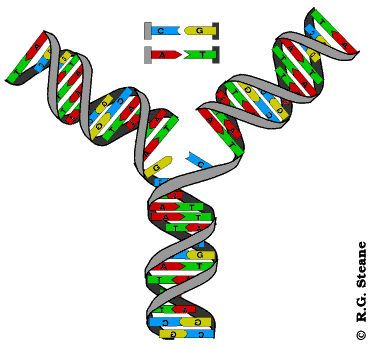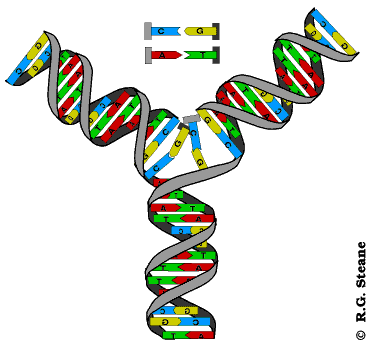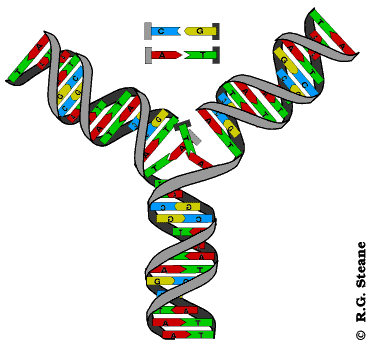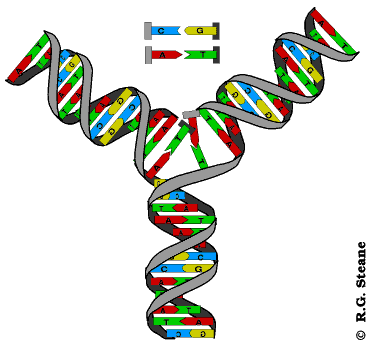
Modélisation animée de la réplication de l'ADN, d'après web.ukonline.co.uk/webwise/ spinneret/genes/andna.htm
1.4 Reploiement de la molécule d'acide désoxyribonucléique
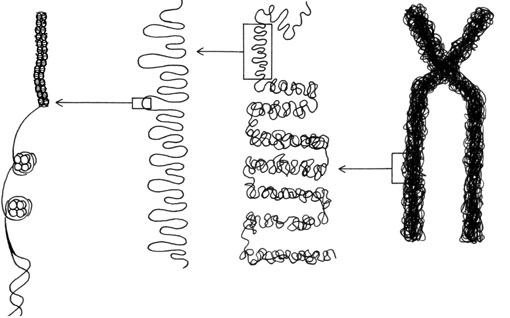
Outre l'ADN, chaque chromosome comprend plus de 50% de protéines, dont certaines, appelées histones, jouent un rôle primordial dans la structuration du chromosome. Les cellules humaines contiennent 46 chromosomes et l'ADN de chacun d'eux a environ 5 cm de long! Plus de deux mètres d'ADN sont donc concentrés dans un noyau de 5 mm de diamètre. La molécule d'ADN s'enroule autour des histones créant autant de nucléosomes, petites unités structurales conférant à la chromatine un aspect granuleux et, à très fort grossissement, donnant aux fibres chromatiniennes un aspect en "collier de perles".
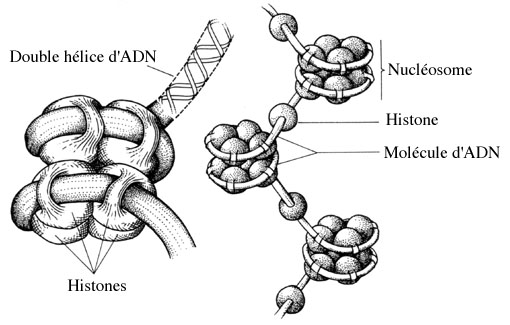
Cette longue succession d'histones peut encore se ramasser sur elle-même pour former le chromosome.
2 Structure de l'acide ribonucléique
Tout comme l'ADN, l'ARN ou acide ribonucléique est un polymère de nucléotides, mais il n'est formé que d'un seul brin, non hélicoïdal, son sucre est le ribose, et, parmi les quatre bases, l'uracile remplace la thymine de l'ADN, avec qui elle partage les affinités d'appariement.
L'ARN intervient dans la synthèse des protéines.
3 Les protéines
3.1 Structure des protéines
3.1.1 Structure primaire des protéines
Les protéines sont des polymères constitués d'un enchaînement de 50 à 500 acides aminés. Un acide aminé comprend une fonction "acide carboxylique" et une fonction "amine", toutes deux portées par un même atome de carbone, auquel sont également liés un atome d'hydrogène et un radical variable, dont il existe 20 types naturels: cela va d'un simple atome d'hydrogène à un groupement cyclique complexe. Les protéines, substances naturelles, sont faites à partir de 20 acides aminés différents qui ne se distinguent que par leur radical.
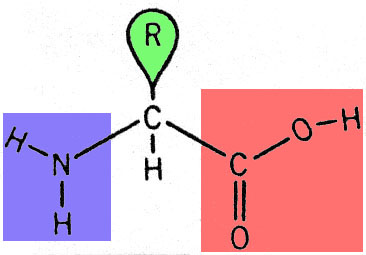
Structure chimique générale d'un acide aminé. La fonction "amine" est indiquée en bleu, la fonction "acide carboxylique" est indiquée en rouge et le radical variable, indiqué en vert, est symbolisé par la lettre "R".
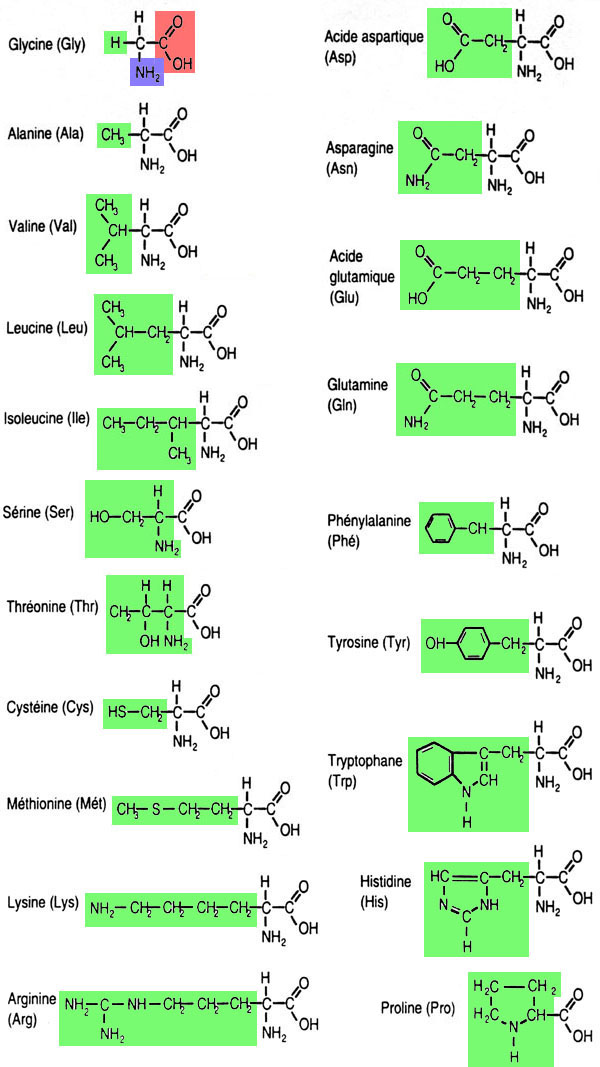
Noms, abréviations et formules chimiques des 20 acides aminés naturels présents dans les protéines. Le radical caractéristique de l'acide aminé est indiqué en vert.
Les monomères que sont les acides aminés sont reliés par des liaisons peptidiques, formées par condensation (=élimination d'une molécule d'eau) entre la fonction "acide carboxylique" d'un acide aminé et la fonction "amine" de l'acide aminé suivant.
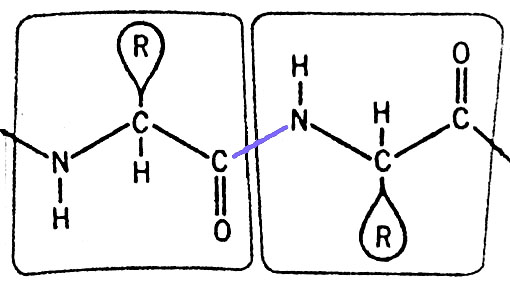
Illustration de la liaison peptidique (en bleu) unissant deux acides aminés.
3.1.2 Structure secondaire des protéines
Outre la structure primaire, au niveau de laquelle les différentes protéines ne se distinguent que par la nature des acides aminés qui se succèdent, la molécule de protéine présente une structure secondaire: des "liaisons hydrogène" ou "ponts hydrogènes", produits entre l'atome d'hydrogène de la fonction "amine" des acides aminés n°X et l'atome d'oxygène de la fonction "acide carboxylique" des acides aminés n°X-4, confèrent à la molécule une forme en hélice, comprenant un peu plus de 3 acides aminés par tour.
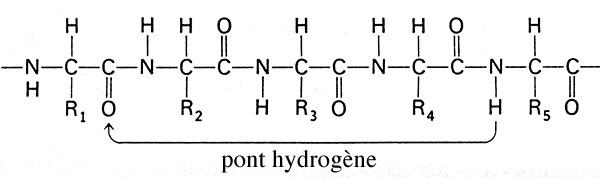
Localisation, sur la structure linéaire primaire d'un polypeptide, d'un des ponts hydrogène responsables de la structure secondaire des protéines.
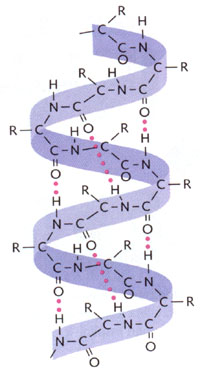
Structure secondaire d'un polypeptide, montrant sa forme hélicoïdale et les ponts hydrogène (points roses) qui en sont responsables (d'après Miller, L., 1994.- Biology. Discovering Life. D. C. Heath and Compagny.).
3.1.3 Structure tertiaire des protéines
La structure tertiaire est la forme selon laquelle la protéine hélicoïdale se replie sur elle-même grâce à des liaisons transversales de faible énergie, ponts hydrogène et surtout ponts disulfures: les atomes de soufre du radical de deux cystéines (-S-H) se lient en éliminant deux atomes d'hydrogène et forment la cystine (-S-S-).
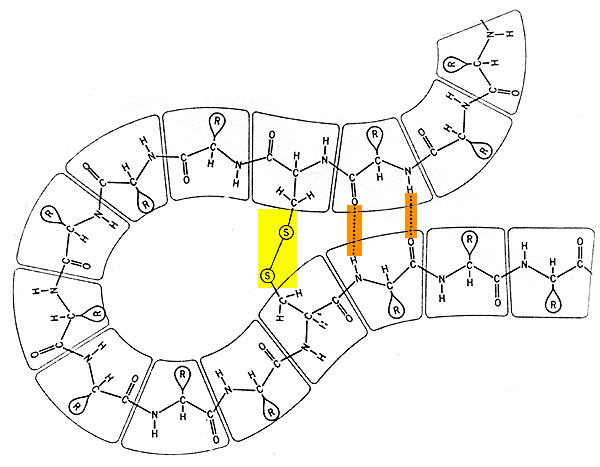
La structure tertiaire est fort variable selon le type de la protéine. Les protéines fibreuses comme les kératines composant les phanères (ongles, griffes, sabots, poils et cheveux) forment de longues chaînes rigides. En les plongeant dans des substances contenant des atomes de soufre et interagissant donc avec les cystines, on détruit provisoirement les ponts disulfures et la protéine perd sa forme: c'est la dénaturation des protéines, qui se réalise aussi grâce à d'autres produits ou à la chaleur. Si l'on retire l'agent dénaturant, la protéine reprend sa forme initiale ou toute autre forme artificiellement imposée. On effectue cette dénaturation-"renaturation" lors de la confection des "permanentes" sur les cheveux féminins.
3.1.4 Structure quaternaire des protéines
Une succession d'acides aminés reliés par des liaisons peptidiques est appelée un polypeptide (éventuellement un oligopeptide si le polymère est court et contient donc peu d'acides aminés). Certaines protéines complexes sont formées par la juxtaposition de plusieurs polypeptides; on parle dès lors de structure quaternaire.
Par exemple, la protéine globuleuse hémoglobine, que nos globules rouges transporteurs d'oxygène contiennent en grande quantité, est un complexe composé de quatre polypeptides, deux chaînes a et deux chaînes b, plus quatre petites molécules appelées hèmes et contenant chacune un atome de fer.
Autre exemple, le collagène est une protéine fibreuse faite de trois polypeptides hélicoïdaux torsadés. C'est la protéine la plus abondante du corps humain: elle renforce les tissus conjonctifs de la peau, des os, des ligaments, des tendons, etc.
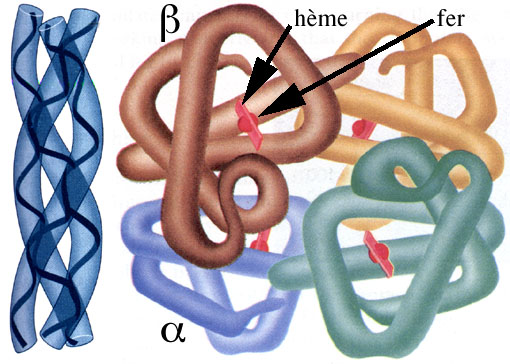
Schémas illustrant la structure quaternaire du collagène (à gauche) et de l'hémoglobine (à droite) (d'après Campbell, N. A., Reece, J. B. & Mitchell, L. G., 1999.- Biology. Addison Wesley Longman et d'après Miller, L., 1994.- Biology. Discovering Life. D. C. Heath and Compagny.).
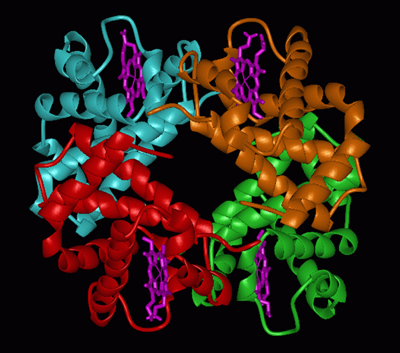
Schémas montrant la structure quaternaire tridimensionnelle de l'hémoglobine (d'après http://www.ccbb.pitt.edu/CCBBResearchDynHemRel.htm).
3.2 Fonction des protéines
Certaines protéines participent à la construction de nos différentes cellules, donc de tout notre corps: la kératine des poils, le collagène des tissus conjonctifs, l'actine et la myosine des muscles,... sont des protéines.
Certaines protéines véhiculent des informations dans notre corps, au niveau du système nerveux (neuropeptides) ou dans le sang (hormones comme l'insuline ou le glucagon).
Beaucoup de protéines globuleuses constituent des enzymes, qui catalysent l'ensemble des réactions métaboliques de notre corps (c'est-à-dire qui accélèrent les réactions chimiques de notre corps sans en changer les équilibres), ce qui permet à ces réactions de se produire rapidement à des températures compatibles avec la vie. Il existe une enzyme spécifique à chaque réaction biochimique. L'enzyme augmente la probabilité de rencontre des réactifs, agissant comme un véritable établi possédant des affinités avec chacun des réactifs.
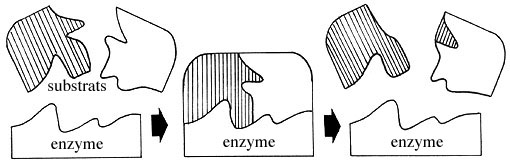
Schéma original simplifié montrant comment une enzyme peut catalyser la réaction entre deux substrats.
3.3 Gènes et code génétique
Nous savons que l'ADN, matériel héréditaire, constitue le plan pour fabriquer les protéines qui sont à la fois les "briques de construction" et les "usines" de notre organisme. La molécule d'ADN donne pour information une succession de bases, chacune à choisir parmi 4 possibilités. Avec une base (ou un nucléotide), il est possible d'effectuer un choix parmi 4 possibilités, avec deux bases un choix parmi 4 X 4, soit 16 possibilités, avec trois bases un choix parmi 4 X 4 X 4, soit 64 possibilités, etc. Or, construire un polypeptide, c'est faire une succession de choix parmi 20 possibilités différentes (les 20 acides aminés). Ainsi, l'information constituée par une base (1 choix sur 4) ou d'un doublet de bases (1 choix sur 16) d'ADN ne suffit pas pour choisir un acide aminé défini parmi 20: il faut l'information d'un triplet, c'est-à-dire trois bases successives d'un brin d'ADN, pour choisir chaque acide aminé du polypeptide à construire. Cette correspondance entre la succession de trois bases d'ADN et chaque acide aminé du polypeptide constitue le code génétique. Celui-ci est universel dans le monde vivant: il est le même pour une bactérie, une cellule de petit pois ou celle d'un éléphant! Il s'agit là d'un excellent argument en faveur d'une origine commune et unique à tous les êtres vivants de la planète.
Il y a 64 combinaisons possibles lorsque l'on considère un triplet de bases choisies chacune parmi 4 bases différentes. Ces 64 triplets excèdent le nombre d'acides aminés naturels (20): il en résulte de nombreux cas de synonymie.
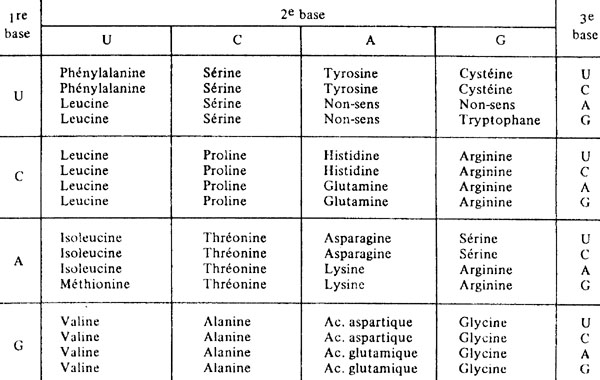
Code génétique universel, commun à tous les êtres vivants. Il s'agit d'une correspondance entre les trois bases d'un codon, soit un triplet de bases d'ARN messager, et l'acide aminé porté par l'ARN de transfert dont l'anticodon est complémentaire au codon.
On appelle gène ou locus toute portion d'ADN dont la succession des bases code pour la synthèse d'une protéine, souvent d'une enzyme (ou de plusieurs enzymes) responsable(s) de l'apparition d'un caractère.
3.4.1 Introduction
Il peut paraître surprenant que l'ADN, situé dans le noyau, dirige la synthèse des protéines qui s'effectue au niveau des ribosomes, dans le cytoplasme. En réalité, une copie de l'ADN nucléaire va voyager du noyau vers les ribosomes: c'est l'acide ribonucléique messager (ARNm) copié lors de la transcription. L'ARNm dicte ensuite aux ribosomes, au cours de la traduction, les séquences d'acides aminés à juxtaposer pour composer les polypeptides.
3.4.2 La transcription
On appelle transcription le mécanisme par lequel l'information portée par l'ADN est copiée en ARN messager. Celui-ci est formé par la succession de nucléotides aux bases complémentaires de celles de l'ADN. Pour effectuer cette transcription, les deux brins d'ADN se séparent comme au cours de la réplication; des nucléotides s'apparient ensuite de façon complémentaire aux bases du brin d'ADN, et constituent, une fois reliés, l'ARNm qui quitte le noyau et gagne les ribosomes. Chaque triplet de bases de l'ADN a donc été copié en un triplet d'ARNm aux bases complémentaires, appelé codon.
3.4.3 La traduction
La traduction correspond à la synthèse d'un polypeptide à partir des codons de l'ARNm. Ce mécanisme exige l'intervention de deux autres types d'ARN: l'ARN ribosomial (ARNr) et l'ARN de transfert (ARNt).
Les ribosomes, au niveau desquels s'effectuent la traduction, sont faits de protéines et d'ARNr, aussi appelé ARN de structure. Outre son rôle de structure, l'ARNr contrôle la traduction. Il prend naissance à partir de l'ARN du nucléole. Le nucléole du noyau cellulaire a donc un triple rôle:
Les petites molécules d'ARNt se trouvent dans le cytoplasme. Elles présentent une forme de trèfle car certaines portions aux bases complémentaires s'apparient par des liaisons hydrogène. Une extrémité de l'ARNt porte une séquence de trois bases (soit un triplet) appelée anticodon: celui-ci représente le complément d'un codon d'ARNm. L'autre extrémité de l'ARNt porte un des 20 acides aminés naturels, dont la nature est strictement déterminée par la nature de l'anticodon.
La synthèse d'un polypeptide se déroule de la façon suivante:
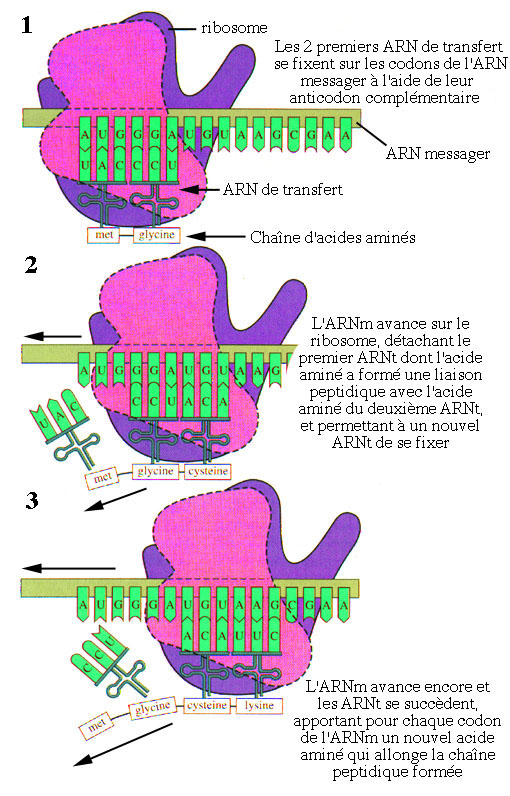
Schéma résumant la traduction des protéines.
Remarquons qu'une molécule d'ARNm s'engage successivement sur plusieurs ribosomes disposés en spirale à la surface du reticulum endoplasmique rugueux: il s'ensuit une série de synthèses, légèrement décalées dans le temps, d'un même polypeptide sur plusieurs ribosomes.
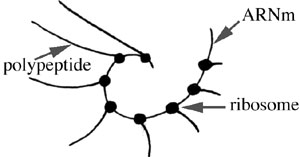
Des enzymes cytoplasmiques assurent la régénération des couples "ARNt-acide aminé" à partir d'ARNt "nus" et d'acides aminés libres dans le cytoplasme.
3.4.4 L'ADN n'est-il qu'une succession de gènes?
Considérer l'ADN comme une succession de gènes codant chacun pour un peptide est un peu simpliste. On sait aujourd'hui, d'après une étude portant sur 1% du génome humain, que seulement 2% de l'ADN code pour des peptides, les 98% restants n'ayant pas d'activité codante identifiée.
On sait aussi que les séquences d'ADN copiées au cours de la transcription sous forme d'ARNm ne sont pas toujours faites d'un seul morceau, mais parfois de fragments non jointifs très éloignés sur la molécule d'ADN.
Enfin, on a découvert que certains ARN, normalement des copies éphémères de l'ADN pour la traduction, constituent en réalité un objet final et non un message pour synthétiser un peptide: parmi ces ARN se trouvent des molécules qui jouent un rôle dans la régulation de processus cellulaires.